Video Moment Retrieval from Natural Language Query.
In this project, we designed a novel algorithm for retrieving video moment from natural language query, got state-of-the-art result on TVR and Charades-STA dataset.
Temporal Attention and Consistency Measuring for Video Question Answering.
 In this paper, we constructed multimodal temporal sequences for video context and the question based on visual features extracted by DenseNet161, audio features extracted by COVAREP and natural language features by BERT model. Designed a temporal attention mechanism that highlights the keywords in the question (person subjects, objects, actions, environmental constraints), key sentences in the transcript and critical moments in the long video. Designed a multi-level consistency measuring module and a reasoning module to infer which candidate answer semantically matches the question most.
In this paper, we constructed multimodal temporal sequences for video context and the question based on visual features extracted by DenseNet161, audio features extracted by COVAREP and natural language features by BERT model. Designed a temporal attention mechanism that highlights the keywords in the question (person subjects, objects, actions, environmental constraints), key sentences in the transcript and critical moments in the long video. Designed a multi-level consistency measuring module and a reasoning module to infer which candidate answer semantically matches the question most.
A multi-stream recurrent neural network for dynamic multiparty human interactive behavior analysis from visual, audio and language.
In this project, we extracted frame-wise visual features including head pose and eye gaze behavior, body movements, facial expression (facial action units). Extracted natural language embedding for transcripts in the video using GloVe model. Extracted acoustic features such as zero-crossing rate, energy, spectral entropy and MFCCs. Performed multimodal fusion for visual, audio and language sequences on a frame-basis.
 Designed a novel LSTM-based deep neural network model that takes multimodal temporal sequences from multiple people as input and captures intra-modality, inter-modality and inter-personal temporal dependencies to predict dynamic social roles (Protagonist, Neutral, Supporter, or Gatekeeper) in the group meeting. Analyzed the importance of various behavior cues that are relevant for dynamic social roles, making the model interpretable.
Designed a novel LSTM-based deep neural network model that takes multimodal temporal sequences from multiple people as input and captures intra-modality, inter-modality and inter-personal temporal dependencies to predict dynamic social roles (Protagonist, Neutral, Supporter, or Gatekeeper) in the group meeting. Analyzed the importance of various behavior cues that are relevant for dynamic social roles, making the model interpretable.
Detecting co-occurrences of actions across multiple people in the interaction for automatic personality traits screening.
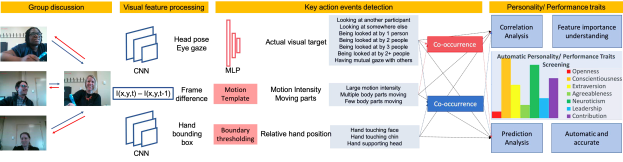 In this project, we detected frame-wise hand positions from 2D video using CNN. Estimated human motion intensity level and number of moving body parts. Constructed co-occurrence patterns that capture the action/ behaviors of the participant herself and her interactions with others, predicted personality traits (Openness, Consciousness, Extraversion, Agreeableness, Neuroticism) scores based on the interactive behavior cues. Analyzed the correlation between behavior cues and personality traits thus making an interpretable model more interpretable.
In this project, we detected frame-wise hand positions from 2D video using CNN. Estimated human motion intensity level and number of moving body parts. Constructed co-occurrence patterns that capture the action/ behaviors of the participant herself and her interactions with others, predicted personality traits (Openness, Consciousness, Extraversion, Agreeableness, Neuroticism) scores based on the interactive behavior cues. Analyzed the correlation between behavior cues and personality traits thus making an interpretable model more interpretable.
Estimating visual focus of attention and combining visual and audio signals for emergent leader prediction.
 In this project, we collected an audio-visual dataset for estimation social signals in multi-people interaction. Annotated social signals including Big-Five personality traits, emergent leadership rating within a group. Designed a neural network-based visual focus of attention estimation algorithm from un-calibrated 2D visual recordings based on eye gaze and head pose to detect the dynamic visual target (i.e., where the person is looking at) at each frame for each participant in the meeting, predicted emergent leader within a group.
In this project, we collected an audio-visual dataset for estimation social signals in multi-people interaction. Annotated social signals including Big-Five personality traits, emergent leadership rating within a group. Designed a neural network-based visual focus of attention estimation algorithm from un-calibrated 2D visual recordings based on eye gaze and head pose to detect the dynamic visual target (i.e., where the person is looking at) at each frame for each participant in the meeting, predicted emergent leader within a group.
Refined RANSAC for 3D primitive shape fitting based on multi-scale local features
3D scanners have been largely used in remote sensing and robot interaction for 3D environment reconstruction, modelling and scene parsing. However, the large scale scanned data lacks structure and semantic interpretation. Without further processing, the information directly gathered from raw point cloud data can be used for maximum distance detection which is far from enough for automatic car driving system or interactive robot sensing. In this project, we developed the algorithm which combines machine learning methods with RANSAC in order to find candidate primitive shapes before expensive RANSAC iteration process, it can help reduce the energy cost as well as maintain the fitting accuracy.
Human Action recognition for videos using Sparse Representation and deep network
This work proposed a deep learning architecture for action detection in videos using over-complete dictionary learning. Through utilizing sparse representation, the proposed approach achieves considerable accuracy compared with state- of- the-art results as well as saving the memory and making the whole procedure faster. The proposed approach was tested on two dataset including Weizmann and KTH action dataset. For Weizmann dataset which contains 10 different classes for human action, our proposed approach achieves the test accuracy 80.4. For KTH dataset which contains 6 different classes for human action, our approach achieves the test accuracy 80.4. We also analyze the relation between sparsity with accuracy and the relation between sparsity with time-consumption of our method, which illustrates that the proper sparsity value in our approach would significantly improves the computing time and achieves considerable accuracy.
Never-lost: Multi-camera face detection and full-body tracking for videos
This project introduced the basic setup and functions of PRPOF, which was built on top of state-of-the-art algorithms and models. The system is aimed at combining face detection and full-body tracking to solve the bottleneck that the tracked face might be occluded or the target is of back view. This two modules form a closed-loop called Never-lost framework, which guarantees the stability and reliability of our system. The face detection part is based on Multi-task CNN deep learning frame work and recognition module is built upon VGG-Net, using the last layer as the representation of our face with the tracking part which is based on the dynamic scale feature correlation estimation. In order to increase accuracy of our model, we use a new dataset called MS-Celeb-1M to train our model, and it proves to be more accurate than the previous dataset we used. Additionally, our system contains the processing part including emotion and gender estimation which can be further used to evaluate the target’s activity.
Semantic image segmentation for 3D scene parsing
In this paper, we propose a new approach to semantic segmentation for 3D point cloud. Different from the traditional CNN architecture, we do 3D feature abstraction of each point before send them into neural network. And the input of neural network is a vector of each point, instead of the whole 3D image. As 3D feature abstraction has aggregated enough local structure information, achieving the same function of complex CNN architecture, our neural network can reach relative high accuracy with quite trivial structure. Finally, semantic segmentation is realized by combining the coordinates information and the label of each point to reconstruct the point cloud. Our lightweight architecture has advantages of small model size, shorting training time and decent accuracy and can be applied to real time scene parsing such as auto-driving and interactive robot sensing.
Personalized Yelp Recommendation based on Big data Analytics
This project aimed at doing big data analysis for yelp dataset, giving more detailed and personalized recommendation sort for users. The project solved the issue that for the general recommendation algorithm, it could be inefficient for customer to find out the best personalized matching item in a short time among a bunch of recommended items. The proposed method is to firstly calculate a set of recommended items using collaborative filtering based on Spark and then arrange them based on the key word matching similarity of user’s personalized input information. For the key word matching similarity, we generalize the key word lists from both yelp business comment data and user’s history searching data using LSI and built word2vec model. After that we sort the values to get the personalized yelp business recommendation result to find the one which matches the user’s request best. In this way, the recommendation system can be more personalized and match potential users with target business more accurately.
External Crime Motivation analysis and Prediction
In our project, we utilize the historical crime data as well as the multi-media environmental data to analysis the effect of the external factors on the crime motivation. We use both numerical features and text features to provide sufficient feature data which can describe the crime point. For the overall pipeline, we have the input data set including the user’s information, user’s current location, route, current date, temperature, rainfall and other relevant environmental information, the system firstly extracted the key points on the route for our research. The key points are the data points which are likely to be unsafe. Secondly, for each key point, with all kinds of features of the point, the system will do prediction about the possibility of crime occurrence. Thirdly, collecting all the key points prediction results, we give the score which for the current route and recommend the route which has the highest score to help users stay safe. Our project provides a general and useful approach based on the obvious data which can be easily acquired for the public to help themselves stay safe. The result of our research can be further combined with other stimulations of the crime motivation to do criminology analysis.
Bachelor’s Thesis – Acquisition system for 3D data cloud using spectral imaging
In this paper, a 3-D reconstruction technique based on single-time structured light projection is introduced. The proposed approach analyzes the deformed pattern of the projected structured light on the 3D object. The object is placed on the stage. We can read X and Y coordinate information of each pixels from the 2-D image. The Z coordinate needs to be calculate by analyzing the deformed fringe projected onto the surface. We generate several single-color sinusoidal fringe patterns with a phase shift. We project the synthetic image of those phase shifting patterns onto object. Then we use spectrometer to separate patterns according to different frequency. We do histogram equalization and filtering as preliminary treatment. We get initial phase distribution by four-step phase shifting algorithm. After phase unwrapping we can finally get phase information of the project which can be used to do 3D reconstruction.
